Rust and C - The Fair Comparison
Introduction
Let's assume that we are starting a project called Project X. It can be an operating system, a database system, a file system, a web protocol, a kernel or kernel module, or any infrastructure project other than what we've said. When such projects are started, one of the most critical decisions is the language in which the project will be written. The preferred language should have as fast runtime as possible and as low resource consumption as possible. Also, this language must have low-level access to the computer hardware in order to perform low-level operations. Quick compilations can also come in handy when developing such large projects, but not as critical as the others we've mentioned. From this perspective, our selection pool is actually not that wide. The languages to be preferred in such real-world projects are mostly C or C++, rarely Assembly, and Rust, which has proven itself in this field in recent years. Now, some of you would say, "Hey! Is that all? D, Ada, Algol 68, Pascal, Bliss, BCPL, where are these languages? Why they are not in the selection pool?". Well, some are dead, some even less used than the Assembly.
Our topic is C and Rust, so we need to exclude Assembly and C++ from our selection pool in order to stick to the topic. So, for Project X, we have Rust and C in the selection pool. Would you prefer C over Rust or Rust over C? Well, you don't need to answer it right now, so please don't rush on the decision right away. Before deciding, this topic might actually help you to make the right decision for your Project X. Don't worry, I actively use C and Rust, and I really like both. So we're not going to glorify one and disgrace the other.
Language Design
C
50 years ago, only a few languages other than Assembly were able to do low-level operations such as writing O.S that can multitask, writing file system, managing memory, etc. However, Assembly was causing readability and maintainability problems in large-scale projects. In such a complex situation, the creation of C(thanks to Dennis Ritchie and Brian Kernighan) brought tremendous solutions. You can do every single low-level operation from a higher level with better syntax without slowing the computers. And, unlike the other high-level languages, C was portable. That was big deal, that's what made C different and better from the rest of them.
There are many reasons why C is still so efficient around the world. When you search for CPU architectures supported by GCC, the results can blow your mind. When you think like a computer, writing C code makes really sense from that perspective. C is so abstract and fast in every point that you could even call it as a "nicer assembly". It keeps things so simple, you can often predict the assembly dump of your code.
Rust
When it comes to high-performance and low-resource consumption for System Engineering, there is no space for languages that have a garbage collector. Although Golang is an exception, in this case, it is insufficient in terms of performance and resource consumption compared to C and C++. Rust Language project started by aiming to provide highly secure concurrent systems and ensure memory security without using Garbage Collector, while at the same time competing with C and C++ in terms of performance and resource consumption.
Rust provides zero-cost high-level abstractions, access to low-level operation when needed and, memory safety by taking care of memory management in compilation time. Because things taken care in compilation time, Rust can compete with C/C++ in resource usage and speed. For example, you can write a C program that segfaults at runtime, but the Rust compiler realizes that this program will encounter a memory problem at runtime and will not compile the program. Since Rust's solutions are implemented on the compiler, compilation requires extensive static analysis, which takes some time.
Memory Management
Memory management in programming languages is a very critical topic. Entrusting memory management to the developer is a dangerous situation, although it depends on the developer. Therefore, high-level languages such as Java, C#, Python, Go provides a Garbage Collector that automatically manages the memory in the background instead of leaving the memory management to the developer. Garbage Collector assumes each unreferenced object in the heap as garbage and releases it from memory. As good as it sounds, taking the memory from the developer and transferring it to a garbage collection is a very costly trade-off in terms of resource usage. The language of choice for Project X or any system implementation language cannot(or should not) afford this cost. This is where Rust shines. Rust can manage the memory without running the Garbage Collector. Of course, that doesn't happen magically. Rust has such a brilliant compiler design that guarantees memory safety.
In Rust
Rust implements some strict concepts to guarantee memory security. Rust has referred to these concepts as 'zero-cost abstractions', meaning they do not affect runtime.
What are these concepts? Let's talk briefly about them.
Ownership:
Set of rules that the compiler checks at compile time.
The ownership rules are:
- Each value in Rust has a variable that’s called its owner.
- There can only be one owner at a time.
- When the owner goes out of scope, the value will be dropped.
Borrow Checker:
Borrow checker performs the compile-time static analysis. It checks whether the program complies with the rules of ownership, it does not allow the compiler to compile the program when it finds anything non-compliance with the rules of ownership.
Lifetimes
Rust, manages the lifetimes in the background by default. It knows how much the life of each value in memory is and provides memory management over them. But sometimes it wants their lifetime to be explicitly defined by the developer.
In C
C leaves the memory management to the developer. It is entirely in the hands of the developer. If the memory allocation and releases are not at the right points, segfault and overflow problems may occur.
So does that make C bad? Absolutely not. It makes it dangerous for sure, but being dangerous doesn't mean being bad. The safety of C is actually directly proportional to the person who works with it. In other words, the danger posed by the knife, varies by the person using the knife.
So, do you want to invest in your experience(if you are an engineer) and the experience of the engineers who will work on your project, or do you want to invest in a compiler?
Statements like "Messing around with memory management in C is a waste of time. We don't waste time with that in Rust" don't make much sense at all. Because when writing Rust, you will have to deal with the 3 concepts(Ownership, Borrowing, Lifetimes) mentioned above that Rust uses to manage memory. These are things that can take as much time as managing the memory in C.
Performance Comparison
The difference between the performance and resource consumption of C and Rust is negligible. Below you can examine the implementations and benchmark results of some computing algorithms in two languages.
gcc (Ubuntu 10.3.0-1ubuntu1) 10.3.0 against rustc 1.55.0 (c8dfcfe04 2021-09-06) LLVM version: 12.0.1
spectral norm
| language | seconds | memory | busy | cpu load |
|---|---|---|---|---|
| gcc C | 0.40 | 872 | 1.58 | 100% 100% 100% 98% |
| Rust | 0.72 | 2,672 | 2.86 | 100% 100% 100% 99% |
gcc C implementation code and compilation details
/* The Computer Language Benchmarks Game
* https://salsa.debian.org/benchmarksgame-team/benchmarksgame/
*
* contributed by Miles
* optimization with 4x4 kernel + intrinsics
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <x86intrin.h>
// compute values of A 4 at a time instead of 1
static inline __m256d eval_A(__m128i i, __m128i j) {
__m128i ONE = _mm_set1_epi32(1);
__m128i ip1 = _mm_add_epi32(i, ONE);
__m128i ipj = _mm_add_epi32(i, j);
__m128i ipjp1 = _mm_add_epi32(ip1, j);
__m128i a = _mm_mullo_epi32(ipj, ipjp1);
a = _mm_srli_epi32(a, 1);
a = _mm_add_epi32(a, ip1);
return _mm256_cvtepi32_pd(a);
}
// compute results over a 4x4 submatrix of A
static inline void kernel(__m256d u, __m256d s[4], __m256d r[4]) {
__m256d f[4], p[4];
// f[i] is each outfix of size 1 for r[i], scaled by u
// p[i] is the product of r[i]
for (int i = 0; i < 4; i++) {
f[i] = _mm256_permute_pd(r[i], 0b0101);
p[i] = _mm256_mul_pd(r[i], f[i]);
__m256d t = _mm256_permute2f128_pd(p[i], p[i], 0x01);
f[i] = _mm256_mul_pd(t, f[i]);
p[i] = _mm256_mul_pd(t, p[i]);
f[i] = _mm256_mul_pd(f[i], u);
}
__m256d w, x, y, z;
// collect p[i] into z, and get reciprocal
x = _mm256_blend_pd(p[0], p[1], 0b1010);
y = _mm256_blend_pd(p[2], p[3], 0b1010);
z = _mm256_blend_pd(x, y, 0b1100);
__m128 q = _mm256_cvtpd_ps(z);
// approximate reciprocal
q = _mm_rcp_ps(q);
x = _mm256_cvtps_pd(q);
// refine with variation of Goldschmidt’s algorithm
w = _mm256_mul_pd(x, z);
y = _mm256_set1_pd(3.0);
z = _mm256_mul_pd(w, x);
w = _mm256_sub_pd(w, y);
x = _mm256_mul_pd(x, y);
z = _mm256_mul_pd(z, w);
z = _mm256_add_pd(z, x);
// broadcast each 1/z over p[i]
x = _mm256_unpacklo_pd(z, z);
y = _mm256_unpackhi_pd(z, z);
w = _mm256_permute2f128_pd(x, x, 1);
z = _mm256_permute2f128_pd(y, y, 1);
p[0] = _mm256_blend_pd(x, w, 0b1100);
p[1] = _mm256_blend_pd(y, z, 0b1100);
p[2] = _mm256_blend_pd(x, w, 0b0011);
p[3] = _mm256_blend_pd(y, z, 0b0011);
// increment each row-sum by the product u / A[i, j..j+3]
for (int i = 0; i < 4; i++) {
__m256d t = _mm256_mul_pd(f[i], p[i]);
s[i] = _mm256_add_pd(s[i], t);
}
}
static void eval_A_times_u(int n, double *u, double *Au) {
// force static schedule since each chunk performs equal amounts of work
#pragma omp parallel for schedule(static)
for (int i = 0; i < n; i += 4) {
__m256d s[4];
for (int k = 0; k < 4; k++)
s[k] = _mm256_set1_pd(0.0);
for (int j = 0; j < n; j += 4) {
__m256d r[4];
// generate the values of A for the 4x4 submatrix with
// upper-left at (i, j)
for (int k = 0; k < 4; k++) {
__m128i x = _mm_set1_epi32(i+k);
__m128i y = _mm_setr_epi32(j, j+1, j+2, j+3);
r[k] = eval_A(x, y);
}
kernel(_mm256_load_pd(u+j), s, r);
}
// sum the values in each s[i] and store in z
__m256d t0 = _mm256_hadd_pd(s[0], s[1]);
__m256d t1 = _mm256_hadd_pd(s[2], s[3]);
__m256d x = _mm256_permute2f128_pd(t0, t1, 0x21);
__m256d y = _mm256_blend_pd(t0, t1, 0b1100);
__m256d z = _mm256_add_pd(x, y);
_mm256_store_pd(Au+i, z);
}
// clear overhang values
Au[n] = 0.0;
Au[n+1] = 0.0;
Au[n+2] = 0.0;
}
// same as above except indices of A flipped (transposed)
static void eval_At_times_u(int n, double *u, double *Au) {
#pragma omp parallel for schedule(static)
for (int i = 0; i < n; i += 4) {
__m256d s[4];
for (int k = 0; k < 4; k++)
s[k] = _mm256_set1_pd(0.0);
for (int j = 0; j < n; j += 4) {
__m256d r[4];
for (int k = 0; k < 4; k++) {
__m128i x = _mm_set1_epi32(i+k);
__m128i y = _mm_setr_epi32(j, j+1, j+2, j+3);
r[k] = eval_A(y, x);
}
kernel(_mm256_load_pd(u+j), s, r);
}
__m256d t0 = _mm256_hadd_pd(s[0], s[1]);
__m256d t1 = _mm256_hadd_pd(s[2], s[3]);
__m256d x = _mm256_permute2f128_pd(t0, t1, 0x21);
__m256d y = _mm256_blend_pd(t0, t1, 0b1100);
__m256d z = _mm256_add_pd(x, y);
_mm256_store_pd(Au+i, z);
}
Au[n] = 0.0;
Au[n+1] = 0.0;
Au[n+2] = 0.0;
}
static void eval_AtA_times_u(int n, double *u, double *AtAu) {
double v[n+3] __attribute__((aligned(sizeof(__m256d))));
eval_A_times_u(n, u, v);
eval_At_times_u(n, v, AtAu);
}
int main(int argc, char *argv[]) {
int n = atoi(argv[1]);
// overhang of 3 values for computing in strides of 4 incase n % 4 != 0
// aligned to __m256d to use aligned loads/stores
double u[n+3] __attribute__((aligned(sizeof(__m256d))));
double v[n+3] __attribute__((aligned(sizeof(__m256d))));
for (int i = 0; i < n; i++)
u[i] = 1.0;
// initiate overhang values to zero
u[n] = 0.0;
u[n+1] = 0.0;
u[n+2] = 0.0;
for (int i = 0; i < 10; i++) {
eval_AtA_times_u(n, u, v);
eval_AtA_times_u(n, v, u);
}
__m256d uv = _mm256_set1_pd(0.0);
__m256d v2 = _mm256_set1_pd(0.0);
for (int i = 0; i < n; i += 4) {
__m256d x = _mm256_load_pd(u+i);
__m256d y = _mm256_load_pd(v+i);
x = _mm256_mul_pd(x, y);
y = _mm256_mul_pd(y, y);
uv = _mm256_add_pd(uv, x);
v2 = _mm256_add_pd(v2, y);
}
__m256d z = _mm256_hadd_pd(uv, v2);
__m128d x = _mm256_extractf128_pd(z, 0);
__m128d y = _mm256_extractf128_pd(z, 1);
x = _mm_add_pd(x, y);
x = _mm_sqrt_pd(x);
double r[2] __attribute__((aligned(sizeof(__m128d))));
_mm_store_pd(r, x);
printf("%0.9f\n", r[0] / r[1]);
return 0;
}
64-bit Ubuntu quad core
gcc (Ubuntu 10.3.0-1ubuntu1) 10.3.0
MAKE:
/usr/bin/gcc -pipe -Wall -O3 -fomit-frame-pointer -march=ivybridge -fopenmp spectralnorm.gcc-6.c -o spectralnorm.gcc-6.gcc_run
rm spectralnorm.gcc-6.c
2.26s to complete and log all make actions
COMMAND LINE:
./spectralnorm.gcc-6.gcc_run 5500
PROGRAM OUTPUT:
1.274224153
Rust implementation code and compilation details
// The Computer Language Benchmarks Game
// http://benchmarksgame.alioth.debian.org/
//
// contributed by the Rust Project Developers
// contributed by Matt Brubeck
// contributed by TeXitoi
// modified by Tung Duong
// contributed by Cristi Cobzarenco (@cristicbz)
// contributed by Andre Bogus
extern crate rayon;
use rayon::prelude::*;
use std::ops::*;
#[derive(Clone, Copy)]
struct F64x2(f64, f64);
impl F64x2 {
pub fn splat(x: f64) -> F64x2 { F64x2(x, x) }
pub fn new(a: f64, b: f64) -> F64x2 { F64x2(a, b) }
pub fn write_to_slice_unaligned(self, slice: &mut [f64]) {
slice[0] = self.0;
slice[1] = self.1;
}
pub fn sum(self) -> f64 {
let mut s = [0f64; 2];
self.write_to_slice_unaligned(&mut s);
s[0] + s[1]
}
}
impl Add for F64x2 {
type Output = Self;
fn add(self, rhs: Self) -> Self {
F64x2(self.0 + rhs.0, self.1 + rhs.1)
}
}
impl Mul for F64x2 {
type Output = Self;
fn mul(self, rhs: Self) -> Self {
F64x2(self.0 * rhs.0, self.1 * rhs.1)
}
}
impl Div for F64x2 {
type Output = Self;
fn div(self, rhs: Self) -> Self {
F64x2(self.0 / rhs.0, self.1 / rhs.1)
}
}
fn main() {
let n = std::env::args().nth(1)
.and_then(|n| n.parse().ok())
.unwrap_or(100);
let answer = spectralnorm(n);
println!("{:.9}", answer);
}
fn spectralnorm(n: usize) -> f64 {
// Group all vectors in pairs of two for SIMD convenience.
assert!(n % 2 == 0, "only even lengths are accepted");
let mut u = vec![F64x2::splat(1.0); n / 2];
let mut v = vec![F64x2::splat(0.0); n / 2];
let mut tmp = vec![F64x2::splat(0.0); n / 2];
for _ in 0..10 {
mult_at_av(&u, &mut v, &mut tmp);
mult_at_av(&v, &mut u, &mut tmp);
}
(dot(&u, &v) / dot(&v, &v)).sqrt()
}
fn mult_at_av(v: &[F64x2], out: &mut [F64x2], tmp: &mut [F64x2]) {
mult(v, tmp, a);
mult(tmp, out, |i, j| a(j, i));
}
fn mult<F>(v: &[F64x2], out: &mut [F64x2], a: F)
where F: Fn([usize; 2], [usize; 2]) -> F64x2 + Sync {
// Parallelize along the output vector, with each pair of slots as a parallelism unit.
out.par_iter_mut().enumerate().for_each(|(i, slot)| {
// We're computing everything in chunks of two so the indces of slot[0] and slot[1] are 2*i
// and 2*i + 1.
let i = 2 * i;
let (i0, i1) = ([i; 2], [i + 1; 2]);
// Each slot in the pair gets its own sum, which is further computed in two f64 lanes (which
// are summed at the end.
let (mut sum0, mut sum1) = (F64x2::splat(0.0), F64x2::splat(0.0));
for (j, x) in v.iter().enumerate() {
let j = [2 * j, 2 * j + 1];
div_and_add(*x, a(i0, j), a(i1, j), &mut sum0, &mut sum1);
}
// Sum the two lanes for each slot.
*slot = F64x2::new(sum0.sum(), sum1.sum());
});
}
fn a(i: [usize; 2], j: [usize; 2]) -> F64x2 {
F64x2::new(((i[0] + j[0]) * (i[0] + j[0] + 1) / 2 + i[0] + 1) as f64,
((i[1] + j[1]) * (i[1] + j[1] + 1) / 2 + i[1] + 1) as f64)
}
fn dot(v: &[F64x2], u: &[F64x2]) -> f64 {
// Vectorised form of dot product: (1) compute dot across two lanes.
let r = u.iter()
.zip(v)
.map(|(&x, &y)| x * y)
.fold(F64x2::splat(0.0), |s, x| s + x);
// (2) sum the two lanes.
r.sum()
}
// Hint that this function should not be inlined. Keep the parallelised code tight, and vectorize
// better.
#[inline(never)]
fn div_and_add(x: F64x2,
a0: F64x2,
a1: F64x2,
s0: &mut F64x2,
s1: &mut F64x2) {
*s0 = *s0 + x / a0;
*s1 = *s1 + x / a1;
}
64-bit Ubuntu quad core
rustc 1.55.0 (c8dfcfe04 2021-09-06)
LLVM version: 12.0.1
MAKE:
/opt/src/rust-1.55.0/bin/rustc -C opt-level=3 -C target-cpu=ivybridge --C codegen-units=1 -L /opt/src/rust-libs spectralnorm.rs -o spectralnorm.rust-5.rust_run
8.68s to complete and log all make actions
COMMAND LINE:
./spectralnorm.rust-5.rust_run 5500
PROGRAM OUTPUT:
1.274224153
binary trees
| language | seconds | memory | busy | cpu load |
|---|---|---|---|---|
| gcc C | 1.54 | 168,832 | 4.35 | 60% 67% 57% 100% |
| Rust | 1.09 | 198,728 | 3.90 | 87% 98% 88% 86% |
gcc C implementation code and compilation details
// The Computer Language Benchmarks Game
// https://salsa.debian.org/benchmarksgame-team/benchmarksgame/
//
// Contributed by Jeremy Zerfas
// Based on the C++ program from Jon Harrop, Alex Mizrahi, and Bruno Coutinho.
#include <stdint.h>
#include <stdlib.h>
#include <stdio.h>
#include <apr_pools.h>
// intptr_t should be the native integer type on most sane systems.
typedef intptr_t intnative_t;
typedef struct tree_node{
struct tree_node * left_Node, * right_Node;
} tree_node;
// Create a binary tree of depth tree_Depth in memory_Pool and return a pointer
// to the created binary tree.
static tree_node * create_Tree(const intnative_t tree_Depth,
apr_pool_t * const memory_Pool){
tree_node * const root_Node=apr_pcalloc(memory_Pool, sizeof(tree_node));
// If tree_Depth is one or more then recursively call create_Tree() in order
// to create the left and right subtrees.
if(tree_Depth>0){
root_Node->left_Node=create_Tree(tree_Depth-1, memory_Pool);
root_Node->right_Node=create_Tree(tree_Depth-1, memory_Pool);
}
return root_Node;
}
// Compute and return the checksum for the binary tree that has root_Node as the
// root node.
static intnative_t compute_Tree_Checksum(const tree_node * const root_Node){
// If there are subtrees then recursively call compute_Tree_Checksum() on
// them and return 1 plus the checksum of those subtrees.
if(root_Node->left_Node && root_Node->right_Node)
return compute_Tree_Checksum(root_Node->left_Node)+
compute_Tree_Checksum(root_Node->right_Node)+1;
// If the function gets here then this is a single node tree so just return
// 1 as the checksum.
return 1;
}
int main(int argc, char *argv[]){
// Set minimum_Tree_Depth to 4 and maximum_Tree_Depth to the maximum of what
// was specified as the argument to the program and minimum_Tree_Depth+2.
const intnative_t minimum_Tree_Depth=4,
maximum_Tree_Depth=atoi(argv[1])<minimum_Tree_Depth+2 ?
minimum_Tree_Depth+2 : atoi(argv[1]);
apr_initialize();
// Create a memory_Pool which will be used for storing both the stretch_Tree
// and the long_Lived_Tree.
apr_pool_t * memory_Pool;
apr_pool_create_unmanaged(&memory_Pool);
// Create a stretch_Tree of depth maximum_Tree_Depth+1, compute its
// checksum, and print its statistics. This work could be done in parallel
// along with all the other tree processing but APR memory pools aren't
// quite as streamlined as other memory pool implementations so it uses less
// resources to do this work by itself and then clear the memory_Pool so
// that most of the memory that was already allocated for the stretch_Tree
// can be reused for the upcoming long_Lived_Tree work rather than having
// APR allocate more memory for memory pools. Unfortunately since the
// long_Lived_Tree is about half the size of the stretch_Tree, this ends up
// wasting about half the memory that was being used by the stretch_Tree.
// APR subpools could be used to use that otherwise wasted memory for the
// processing of other trees that will be done later but it appears subpools
// only work with managed pools (even though APR's documentation for the
// apr_pool_create_unmanaged_ex() function seems to suggest that it possibly
// should work for unmanaged pools too) which are noticeably slower than
// unmanaged memory pools.
tree_node * stretch_Tree=create_Tree(maximum_Tree_Depth+1, memory_Pool);
printf("stretch tree of depth %jd\t check: %jd\n",
(intmax_t)maximum_Tree_Depth+1,
(intmax_t)compute_Tree_Checksum(stretch_Tree));
apr_pool_clear(memory_Pool);
// The long_Lived_Tree will be created in just a little bit simultaneously
// (assuming OpenMP was enabled and the program is running on a multi-
// processor system) while the rest of the trees are also being processed.
// long_Lived_Tree will store the reference to it which will remain valid
// until near the end of the program.
tree_node * long_Lived_Tree;
// These will be used to store checksums for the various trees so the
// statistics for the various trees can be output in the correct order
// later.
intnative_t long_Lived_Tree_Checksum,
tree_Checksums[(maximum_Tree_Depth-minimum_Tree_Depth+2)/2];
#pragma omp parallel
{
// Have one thread create the long_Lived_Tree of depth
// maximum_Tree_Depth in the memory_Pool which was already previously
// used for the stretch_Tree, compute the long_Lived_Tree_Checksum, and
// then just leave the long_Lived_Tree alone for a while while the rest
// of the binary trees finish processing (which should have
// simultaneously been started to be processed by any other available
// threads).
#pragma omp single nowait
{
long_Lived_Tree=create_Tree(maximum_Tree_Depth, memory_Pool);
long_Lived_Tree_Checksum=compute_Tree_Checksum(long_Lived_Tree);
}
// Create a thread_Memory_Pool for this thread to use.
apr_pool_t * thread_Memory_Pool;
apr_pool_create_unmanaged(&thread_Memory_Pool);
#pragma omp for nowait
for(intnative_t tree_Depth=minimum_Tree_Depth;
tree_Depth<=maximum_Tree_Depth; tree_Depth+=2){
// Create a bunch of binary trees of depth tree_Depth, compute their
// checksums, and add the checksums to the total_Trees_Checksum.
intnative_t total_Trees_Checksum=0;
for(intnative_t iterations=
1<<(maximum_Tree_Depth-tree_Depth+minimum_Tree_Depth);
iterations-->0;){
apr_pool_clear(thread_Memory_Pool);
total_Trees_Checksum+=compute_Tree_Checksum(
create_Tree(tree_Depth, thread_Memory_Pool));
}
// Record the total_Trees_Checksum for the trees of depth
// tree_Depth.
tree_Checksums[(tree_Depth-minimum_Tree_Depth)/2]=
total_Trees_Checksum;
}
apr_pool_destroy(thread_Memory_Pool);
}
// Print the statistics for all of the various tree depths.
for(intnative_t tree_Depth=minimum_Tree_Depth;
tree_Depth<=maximum_Tree_Depth; tree_Depth+=2)
printf("%jd\t trees of depth %jd\t check: %jd\n",
(intmax_t)1<<(maximum_Tree_Depth-tree_Depth+minimum_Tree_Depth),
(intmax_t)tree_Depth,
(intmax_t)tree_Checksums[(tree_Depth-minimum_Tree_Depth)/2]);
// Print the statistics for the long_Lived_Tree that was processed earlier
// and then delete the memory_Pool that still is storing it up to this
// point. Note that although the long_Lived_Tree variable isn't used here,
// it still is in scope and valid to use until the call to
// apr_pool_destroy(memory_Pool) is made.
printf("long lived tree of depth %jd\t check: %jd\n",
(intmax_t)maximum_Tree_Depth,
(intmax_t)long_Lived_Tree_Checksum);
apr_pool_destroy(memory_Pool);
apr_terminate();
return 0;
}
64-bit Ubuntu quad core
gcc (Ubuntu 10.3.0-1ubuntu1) 10.3.0
MAKE:
/usr/bin/gcc -pipe -Wall -O3 -fomit-frame-pointer -march=ivybridge -fopenmp -I/usr/include/apr-1.0 binarytrees.gcc-2.c -o binarytrees.gcc-2.gcc_run -lapr-1
rm binarytrees.gcc-2.c
2.13s to complete and log all make actions
COMMAND LINE:
./binarytrees.gcc-2.gcc_run 21
PROGRAM OUTPUT:
stretch tree of depth 22 check: 8388607
2097152 trees of depth 4 check: 65011712
524288 trees of depth 6 check: 66584576
131072 trees of depth 8 check: 66977792
32768 trees of depth 10 check: 67076096
8192 trees of depth 12 check: 67100672
2048 trees of depth 14 check: 67106816
512 trees of depth 16 check: 67108352
128 trees of depth 18 check: 67108736
32 trees of depth 20 check: 67108832
long lived tree of depth 21 check: 4194303
Rust implementation code and compilation details
// The Computer Language Benchmarks Game
// http://benchmarksgame.alioth.debian.org/
//
// contributed by the Rust Project Developers
// contributed by TeXitoi
// contributed by Cristi Cobzarenco
// contributed by Matt Brubeck
// modified by Tom Kaitchuck
// modified by Volodymyr M. Lisivka
// modified by Ryohei Machida
extern crate bumpalo;
extern crate rayon;
use bumpalo::Bump;
use rayon::prelude::*;
#[derive(Debug, PartialEq, Clone, Copy)]
struct Tree<'a> {
left: Option<&'a Tree<'a>>,
right: Option<&'a Tree<'a>>,
}
fn item_check(tree: &Tree) -> i32 {
if let (Some(left), Some(right)) = (tree.left, tree.right) {
1 + item_check(right) + item_check(left)
} else {
1
}
}
fn bottom_up_tree<'r>(arena: &'r Bump, depth: i32) -> &'r Tree<'r> {
let tree = arena.alloc(Tree { left: None, right: None });
if depth > 0 {
tree.right = Some(bottom_up_tree(arena, depth - 1));
tree.left = Some(bottom_up_tree(arena, depth - 1));
}
tree
}
fn inner(depth: i32, iterations: i32) -> String {
let chk: i32 = (0..iterations)
.into_par_iter()
.map(|_| {
let arena = Bump::new();
let a = bottom_up_tree(&arena, depth);
item_check(a)
})
.sum();
format!("{}\t trees of depth {}\t check: {}", iterations, depth, chk)
}
fn main() {
let n = std::env::args().nth(1).and_then(|n| n.parse().ok()).unwrap_or(10);
let min_depth = 4;
let max_depth = if min_depth + 2 > n { min_depth + 2 } else { n };
{
let arena = Bump::new();
let depth = max_depth + 1;
let tree = bottom_up_tree(&arena, depth);
println!(
"stretch tree of depth {}\t check: {}",
depth,
item_check(tree)
);
}
let long_lived_arena = Bump::new();
let long_lived_tree = bottom_up_tree(&long_lived_arena, max_depth);
let messages = (min_depth / 2..=max_depth / 2)
.into_par_iter()
.map(|half_depth| {
let depth = half_depth * 2;
let iterations = 1 << ((max_depth - depth + min_depth) as u32);
let res = inner(depth, iterations);
res
})
.collect::<Vec<_>>();
for message in messages {
println!("{}", message);
}
println!(
"long lived tree of depth {}\t check: {}",
max_depth,
item_check(long_lived_tree)
);
}
64-bit Ubuntu quad core
rustc 1.55.0 (c8dfcfe04 2021-09-06)
LLVM version: 12.0.1
MAKE:
/opt/src/rust-1.55.0/bin/rustc -C opt-level=3 -C target-cpu=ivybridge --C codegen-units=1 -L /opt/src/rust-libs binarytrees.rs -o binarytrees.rust-5.rust_run
9.82s to complete and log all make actions
COMMAND LINE:
./binarytrees.rust-5.rust_run 21
PROGRAM OUTPUT:
stretch tree of depth 22 check: 8388607
2097152 trees of depth 4 check: 65011712
524288 trees of depth 6 check: 66584576
131072 trees of depth 8 check: 66977792
32768 trees of depth 10 check: 67076096
8192 trees of depth 12 check: 67100672
2048 trees of depth 14 check: 67106816
512 trees of depth 16 check: 67108352
128 trees of depth 18 check: 67108736
32 trees of depth 20 check: 67108832
long lived tree of depth 21 check: 4194303
n body
| language | seconds | memory | busy | cpu load |
|---|---|---|---|---|
| gcc C | 2.18 | 768 | 2.19 | 0% 100% 0% 0% |
| Rust | 3.29 | 1,196 | 3.33 | 0% 100% 1% 0% |
gcc C implementation code and compilation details
/* The Computer Language Benchmarks Game
* https://salsa.debian.org/benchmarksgame-team/benchmarksgame/
*
* contributed by Miles
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <x86intrin.h>
#define N 5
#define PI 3.141592653589793
#define SOLAR_MASS (4 * PI * PI)
#define DAYS_PER_YEAR 365.24
#define PAIRS (N*(N-1)/2)
// utilize vrsqrtps to compute an approximation of 1/sqrt(x) with float,
// cast back to double and refine using a variation of
// Goldschmidt’s algorithm to get < 1e-9 error
static inline __m256d _mm256_rsqrt_pd(__m256d s) {
__m128 q = _mm256_cvtpd_ps(s);
q = _mm_rsqrt_ps(q);
__m256d x = _mm256_cvtps_pd(q);
__m256d y = s * x * x;
__m256d a = _mm256_mul_pd(y, _mm256_set1_pd(0.375));
a = _mm256_mul_pd(a, y);
__m256d b = _mm256_mul_pd(y, _mm256_set1_pd(1.25));
b = _mm256_sub_pd(b, _mm256_set1_pd(1.875));
y = _mm256_sub_pd(a, b);
x = _mm256_mul_pd(x, y);
return x;
}
// compute rsqrt of distance between each pair of bodies
static inline void kernel(__m256d *r, double *w, __m256d *p) {
for (int i = 1, k = 0; i < N; i++)
for (int j = 0; j < i; j++, k++)
r[k] = _mm256_sub_pd(p[i], p[j]);
for (int k = 0; k < PAIRS; k += 4) {
__m256d x0 = _mm256_mul_pd(r[k ], r[k ]);
__m256d x1 = _mm256_mul_pd(r[k+1], r[k+1]);
__m256d x2 = _mm256_mul_pd(r[k+2], r[k+2]);
__m256d x3 = _mm256_mul_pd(r[k+3], r[k+3]);
__m256d t0 = _mm256_hadd_pd(x0, x1);
__m256d t1 = _mm256_hadd_pd(x2, x3);
__m256d y0 = _mm256_permute2f128_pd(t0, t1, 0x21);
__m256d y1 = _mm256_blend_pd(t0, t1, 0b1100);
__m256d z = _mm256_add_pd(y0, y1);
z = _mm256_rsqrt_pd(z);
_mm256_store_pd(w+k, z);
}
}
static double energy(double *m, __m256d *p, __m256d *v) {
double e = 0.0;
__m256d r[PAIRS+3];
double w[PAIRS+3] __attribute__((aligned(sizeof(__m256d))));
r[N] = _mm256_set1_pd(0.0);
r[N+1] = _mm256_set1_pd(0.0);
r[N+2] = _mm256_set1_pd(0.0);
for (int k = 0; k < N; k++)
r[k] = _mm256_mul_pd(v[k], v[k]);
for (int k = 0; k < N; k += 4) {
__m256d t0 = _mm256_hadd_pd(r[k ], r[k+1]);
__m256d t1 = _mm256_hadd_pd(r[k+2], r[k+3]);
__m256d y0 = _mm256_permute2f128_pd(t0, t1, 0x21);
__m256d y1 = _mm256_blend_pd(t0, t1, 0b1100);
__m256d z = _mm256_add_pd(y0, y1);
_mm256_store_pd(w+k, z);
}
for (int k = 0; k < N; k++)
e += 0.5 * m[k] * w[k];
r[PAIRS] = _mm256_set1_pd(1.0);
r[PAIRS+1] = _mm256_set1_pd(1.0);
r[PAIRS+2] = _mm256_set1_pd(1.0);
kernel(r, w, p);
for (int i = 1, k = 0; i < N; i++)
for (int j = 0; j < i; j++, k++)
e -= m[i] * m[j] * w[k];
return e;
}
static void advance(int n, double dt, double *m, __m256d *p, __m256d *v) {
__m256d r[PAIRS+3];
double w[PAIRS+3] __attribute__((aligned(sizeof(__m256d))));
r[PAIRS] = _mm256_set1_pd(1.0);
r[PAIRS+1] = _mm256_set1_pd(1.0);
r[PAIRS+2] = _mm256_set1_pd(1.0);
__m256d rt = _mm256_set1_pd(dt);
__m256d rm[N];
for (int i = 0; i < N; i++)
rm[i] = _mm256_set1_pd(m[i]);
for (int s = 0; s < n; s++) {
kernel(r, w, p);
for (int k = 0; k < PAIRS; k += 4) {
__m256d x = _mm256_load_pd(w+k);
__m256d y = _mm256_mul_pd(x, x);
__m256d z = _mm256_mul_pd(x, rt);
x = _mm256_mul_pd(y, z);
_mm256_store_pd(w+k, x);
}
for (int i = 1, k = 0; i < N; i++)
for (int j = 0; j < i; j++, k++) {
__m256d t = _mm256_set1_pd(w[k]);
t = _mm256_mul_pd(r[k], t);
__m256d x = _mm256_mul_pd(t, rm[j]);
__m256d y = _mm256_mul_pd(t, rm[i]);
v[i] = _mm256_sub_pd(v[i], x);
v[j] = _mm256_add_pd(v[j], y);
}
for (int i = 0; i < N; i++) {
__m256d t = _mm256_mul_pd(v[i], rt);
p[i] = _mm256_add_pd(p[i], t);
}
}
}
int main(int argc, char *argv[]) {
int n = atoi(argv[1]);
double m[N];
__m256d p[N], v[N];
// sun
m[0] = SOLAR_MASS;
p[0] = _mm256_set1_pd(0.0);
v[0] = _mm256_set1_pd(0.0);
// jupiter
m[1] = 9.54791938424326609e-04 * SOLAR_MASS;
p[1] = _mm256_setr_pd(0.0,
4.84143144246472090e+00,
-1.16032004402742839e+00,
-1.03622044471123109e-01);
v[1] = _mm256_setr_pd(0.0,
1.66007664274403694e-03 * DAYS_PER_YEAR,
7.69901118419740425e-03 * DAYS_PER_YEAR,
-6.90460016972063023e-05 * DAYS_PER_YEAR);
// saturn
m[2] = 2.85885980666130812e-04 * SOLAR_MASS;
p[2] = _mm256_setr_pd(0.0,
8.34336671824457987e+00,
4.12479856412430479e+00,
-4.03523417114321381e-01);
v[2] = _mm256_setr_pd(0.0,
-2.76742510726862411e-03 * DAYS_PER_YEAR,
4.99852801234917238e-03 * DAYS_PER_YEAR,
2.30417297573763929e-05 * DAYS_PER_YEAR);
// uranus
m[3] = 4.36624404335156298e-05 * SOLAR_MASS;
p[3] = _mm256_setr_pd(0.0,
1.28943695621391310e+01,
-1.51111514016986312e+01,
-2.23307578892655734e-01);
v[3] = _mm256_setr_pd(0.0,
2.96460137564761618e-03 * DAYS_PER_YEAR,
2.37847173959480950e-03 * DAYS_PER_YEAR,
-2.96589568540237556e-05 * DAYS_PER_YEAR);
// neptune
m[4] = 5.15138902046611451e-05 * SOLAR_MASS;
p[4] = _mm256_setr_pd(0.0,
1.53796971148509165e+01,
-2.59193146099879641e+01,
1.79258772950371181e-01);
v[4] = _mm256_setr_pd(0.0,
2.68067772490389322e-03 * DAYS_PER_YEAR,
1.62824170038242295e-03 * DAYS_PER_YEAR,
-9.51592254519715870e-05 * DAYS_PER_YEAR);
// offset momentum
__m256d o = _mm256_set1_pd(0.0);
for (int i = 0; i < N; i++) {
__m256d t = _mm256_mul_pd(_mm256_set1_pd(m[i]), v[i]);
o = _mm256_add_pd(o, t);
}
v[0] = _mm256_mul_pd(o, _mm256_set1_pd(-1.0 / SOLAR_MASS));
printf("%.9f\n", energy(m, p, v));
advance(n, 0.01, m, p, v);
printf("%.9f\n", energy(m, p, v));
return 0;
}
64-bit Ubuntu quad core
gcc (Ubuntu 10.3.0-1ubuntu1) 10.3.0
MAKE:
/usr/bin/gcc -pipe -Wall -O3 -fomit-frame-pointer -march=ivybridge nbody.gcc-9.c -o nbody.gcc-9.gcc_run
rm nbody.gcc-9.c
2.03s to complete and log all make actions
COMMAND LINE:
./nbody.gcc-9.gcc_run 50000000
PROGRAM OUTPUT:
-0.169075164
-0.169059907
Rust implementation code and compilation details
/// The Computer Language Benchmarks Game
/// https://salsa.debian.org/benchmarksgame-team/benchmarksgame/
///
/// contributed by Mark C. Lewis
/// modified slightly by Chad Whipkey
/// converted from java to c++,added sse support, by Branimir Maksimovic
/// converted from c++ to c, by Alexey Medvedchikov
/// converted from c to Rust by Frank Rehberger
///
/// As the code of `gcc #4` this code requires hardware supporting
/// the CPU feature SSE2, implementing SIMD operations.
///
/// As for `gcc` the operation symbols `*` and `+` etc. are overloaded
/// for SIMD data type _m128f (2x double float SIMD data type); the
/// compiler `gcc` will map the symbols `+`, `*`, `-`, `/` onto
/// corresponding SIMD instructions, namely `_mm_mul_pd`, `_mm_div_pd`,
/// `_mm_add_pd`, and `_mm_sub_pd`. In Rust these SIMD-operations are
/// invoked explicitly.
///
/// The following Rust code contains comments, in case the Rust code
/// requires a different layout; the comment is referring to the
/// corresponding expression in `gcc #4`
const PI: f64 = 3.141592653589793;
const SOLAR_MASS: f64 = 4.0 * PI * PI;
const YEAR: f64 = 365.24;
const N_BODIES: usize = 5;
use std::arch::x86_64::*;
/// Datatype respresenting a Planet
///
/// The annotation `repr(C)` prevents the Rust-compiler from any
/// re-ordering of members.
///
/// Corresponding to `gcc #4`
/// ```
/// struct body {
/// double x[3], fill, v[3], mass;
/// };
/// ```
#[repr(C)]
#[derive(Clone, Copy)]
struct Body {
x: [f64; 3],
fill: f64,
v: [f64; 3],
mass: f64,
}
static BODIES: [Body; N_BODIES] = [
// Sun
Body {
x: [0.0, 0.0, 0.0],
fill: 0.0,
v: [0.0, 0.0, 0.0],
mass: SOLAR_MASS,
},
// Jupiter
Body {
x: [
4.84143144246472090e+00,
-1.16032004402742839e+00,
-1.03622044471123109e-01,
],
fill: 0.0,
v: [
1.66007664274403694e-03 * YEAR,
7.69901118419740425e-03 * YEAR,
-6.90460016972063023e-05 * YEAR,
],
mass: 9.54791938424326609e-04 * SOLAR_MASS,
},
// Saturn
Body {
x: [
8.34336671824457987e+00,
4.12479856412430479e+00,
-4.03523417114321381e-01,
],
fill: 0.0,
v: [
-2.76742510726862411e-03 * YEAR,
4.99852801234917238e-03 * YEAR,
2.30417297573763929e-05 * YEAR,
],
mass: 2.85885980666130812e-04 * SOLAR_MASS,
},
// Uranus
Body {
x: [
1.28943695621391310e+01,
-1.51111514016986312e+01,
-2.23307578892655734e-01,
],
fill: 0.0,
v: [
2.96460137564761618e-03 * YEAR,
2.37847173959480950e-03 * YEAR,
-2.96589568540237556e-05 * YEAR,
],
mass: 4.36624404335156298e-05 * SOLAR_MASS,
},
// Neptune
Body {
x: [
1.53796971148509165e+01,
-2.59193146099879641e+01,
1.79258772950371181e-01,
],
fill: 0.0,
v: [
2.68067772490389322e-03 * YEAR,
1.62824170038242295e-03 * YEAR,
-9.51592254519715870e-05 * YEAR,
],
mass: 5.15138902046611451e-05 * SOLAR_MASS,
},
];
/// A named type declaration corresponding to the anonymous type declaration in `gcc #4`:
/// ```
/// static struct {
/// double dx[3], fill;
/// } ...
/// ```
/// The annotation `repr(C)` prevents the Rust-compiler from any
/// re-ordering of members.
#[repr(C)]
#[derive(Clone, Copy)]
struct Delta {
dx: [f64; 3],
fill: f64,
}
/// Default constructor of Delta
impl Default for Delta {
fn default() -> Delta {
Delta {
dx: [0.0, 0.0, 0.0],
fill: 0.0,
}
}
}
/// Calculating the offset momentum
fn offset_momentum(bodies: &mut [Body; N_BODIES]) {
for i in 0..bodies.len() {
for k in 0..3 {
bodies[0].v[k] -= bodies[i].v[k] * bodies[i].mass / SOLAR_MASS;
}
}
}
/// Calculating the energy of the N body system
fn bodies_energy(bodies: &[Body; N_BODIES]) -> f64 {
let mut dx: [f64; 3] = [0.0; 3];
let mut e = 0.0;
for i in 0..bodies.len() {
e += bodies[i].mass
* ((bodies[i].v[0] * bodies[i].v[0])
+ (bodies[i].v[1] * bodies[i].v[1])
+ (bodies[i].v[2] * bodies[i].v[2]))
/ 2.0;
for j in (i + 1)..bodies.len() {
for k in 0..3 {
dx[k] = bodies[i].x[k] - bodies[j].x[k];
}
let distance = ((dx[0] * dx[0]) + (dx[1] * dx[1]) + (dx[2] * dx[2])).sqrt();
e -= (bodies[i].mass * bodies[j].mass) / distance;
}
}
e
}
/// Declaring an array of f64, starting at memory address, being aligned by 16
///
/// This is corresponding to the anonymous type-declaration being used in `gcc #4`
/// ```
/// static __attribute__((aligned(16))) double mag[1000];
/// ```
/// The annotation `repr(C)` prevents the Rust-compiler from any
/// re-ordering of members.
#[repr(C)]
#[repr(align(16))]
#[derive(Clone, Copy)]
struct AlignedF64Array([f64; 1000]);
/// Representing the arrays `r` and `mag`, being re-used every iteration
///
/// This is corresponding to the following code in `gcc #4`
/// ```
/// static struct {
/// double dx[3], fill;
/// } r[1000];
/// static __attribute__((aligned(16))) double mag[1000];
/// ```
struct BodiesAdvance {
r: [Delta; 1000],
mag: AlignedF64Array,
}
/// Implementation of instanciating the buffers and function bodies_advance()
impl BodiesAdvance {
// Constructor, instanciating the buffers `r` and `mag`
pub fn new() -> BodiesAdvance {
BodiesAdvance {
r: [Delta::default(); 1000],
mag: AlignedF64Array([0.0; 1000]),
}
}
/// Calculating advance of bodies within time dt, using the buffers `r` and `mag`
#[inline]
pub fn bodies_advance(&mut self, bodies: &mut [Body; N_BODIES], dt: f64) {
#[allow(non_snake_case)]
let N = ((bodies.len() - 1) * bodies.len()) / 2;
// In `gcc #4` corresponding to local variable declaration dx
// inititalizing 2x64byte floats with zeros
// ```
// __m128d dx[3];
// ```
let mut dx: [__m128d; 3] = unsafe { [_mm_setzero_pd(); 3] };
let mut k = 0;
for i in 0..(bodies.len() - 1) {
for j in (i + 1)..bodies.len() {
for m in 0..3 {
self.r[k].dx[m] = bodies[i].x[m] - bodies[j].x[m];
}
k += 1;
}
}
// enumerate in +2 steps
for i_2 in 0..(N / 2) {
let i = i_2 * 2;
for m in 0..3 {
dx[m] = unsafe { _mm_loadl_pd(dx[m], &self.r[i].dx[m]) };
dx[m] = unsafe { _mm_loadh_pd(dx[m], &self.r[i + 1].dx[m]) };
}
// In `gcc #4` corresponding to implicit call of _m128f operations
// ```
// dsquared = dx[0] * dx[0] + dx[1] * dx[1] + dx[2] * dx[2];
// ```
let dsquared: __m128d = unsafe {
_mm_add_pd(
_mm_add_pd(_mm_mul_pd(dx[0], dx[0]), _mm_mul_pd(dx[1], dx[1])),
_mm_mul_pd(dx[2], dx[2]),
)
};
// In `gcc #4` corresponding to call of _m128f operations
// ```
// distance = _mm_cvtps_pd(_mm_rsqrt_ps(_mm_cvtpd_ps(dsquared)))
// ```
let mut distance = unsafe { _mm_cvtps_pd(_mm_rsqrt_ps(_mm_cvtpd_ps(dsquared))) };
// repeat 2 times
for _ in 0..2 {
// In `gcc #4` corresponding to implicit call of _m128f operations
// ```
// distance = distance * _mm_set1_pd(1.5)
// - ((_mm_set1_pd(0.5) * dsquared) * distance)
// * (distance * distance);
// ```
distance = unsafe {
_mm_sub_pd(
_mm_mul_pd(distance, _mm_set1_pd(1.5)),
_mm_mul_pd(
_mm_mul_pd(_mm_mul_pd(_mm_set1_pd(0.5), dsquared), distance),
_mm_mul_pd(distance, distance),
),
)
};
}
// In `gcc #4` corresponding to implicit call of _m128f operations
// ```
// dmag = _mm_set1_pd(dt) / (dsquared) * distance;
// ```
let dmag: __m128d =
unsafe { _mm_mul_pd(_mm_div_pd(_mm_set1_pd(dt), dsquared), distance) };
// In `gcc #4` corresponding to call of _m128f operations
// ```
// _mm_store_pd(&mag[i], dmag);
// ```
unsafe {
_mm_store_pd(&mut (self.mag.0)[i], dmag);
}
}
let mut k = 0;
for i in 0..(bodies.len() - 1) {
for j in (i + 1)..bodies.len() {
for m in 0..3 {
bodies[i].v[m] -= (self.r[k].dx[m] * bodies[j].mass) * (self.mag.0)[k];
bodies[j].v[m] += (self.r[k].dx[m] * bodies[i].mass) * (self.mag.0)[k];
}
k += 1;
}
}
for i in 0..bodies.len() {
for m in 0..3 {
bodies[i].x[m] += dt * bodies[i].v[m];
}
}
}
}
fn main() {
let ncycles = std::env::args_os()
.nth(1)
.and_then(|s| s.into_string().ok())
.and_then(|n| n.parse().ok())
.unwrap_or(1000);
let mut bodies = BODIES;
let mut sim = BodiesAdvance::new();
offset_momentum(&mut bodies);
println!("{:.9}", bodies_energy(&bodies));
for _ in 0..ncycles {
sim.bodies_advance(&mut bodies, 0.01);
}
println!("{:.9}", bodies_energy(&bodies));
}
64-bit Ubuntu quad core
rustc 1.55.0 (c8dfcfe04 2021-09-06)
LLVM version: 12.0.1
MAKE:
/opt/src/rust-1.55.0/bin/rustc -C opt-level=3 -C target-cpu=ivybridge --C codegen-units=1 nbody.rs -o nbody.rust-7.rust_run
6.74s to complete and log all make actions
COMMAND LINE:
./nbody.rust-7.rust_run 50000000
PROGRAM OUTPUT:
-0.169075164
-0.169059907
regex redux
| language | seconds | memory | busy | cpu load |
|---|---|---|---|---|
| gcc C | 0.80 | 152,172 | 2.01 | 52% 99% 48% 53% |
| Rust | 0.77 | 147,524 | 1.99 | 54% 59% 91% 54% |
gcc C implementation code and compilation details
// The Computer Language Benchmarks Game
// https://salsa.debian.org/benchmarksgame-team/benchmarksgame/
//
// contributed by Jeremy Zerfas
// modified by Zoltan Herczeg
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define PCRE2_CODE_UNIT_WIDTH 8
#include "pcre2.h"
typedef struct {
PCRE2_UCHAR *data;
PCRE2_SIZE capacity, size;
} string;
// Function for searching a src_String for a pattern, replacing it with some
// specified replacement, and storing the result in dst_String.
static void replace(char const * const pattern, char const * const replacement
, string const * const src_String, string * const dst_String
, pcre2_match_context * const mcontext, pcre2_match_data * mdata){
int errorcode;
PCRE2_SIZE erroroffset, pos=0;
int const replacement_Size=strlen(replacement);
PCRE2_SIZE *match=pcre2_get_ovector_pointer(mdata);
// Compile and study pattern.
pcre2_code * regex=pcre2_compile((PCRE2_SPTR)pattern, PCRE2_ZERO_TERMINATED
, 0, &errorcode, &erroroffset, NULL);
pcre2_jit_compile(regex, PCRE2_JIT_COMPLETE);
// Find each match of the pattern in src_String and append the characters
// preceding each match and the replacement text to dst_String.
while(pcre2_jit_match(regex, src_String->data, src_String->size, pos, 0
, mdata, mcontext)>=0){
// Allocate more memory for dst_String if there is not enough space for
// the characters preceding the match and the replacement text.
while(dst_String->size+match[0]-pos+replacement_Size
>dst_String->capacity)
dst_String->data=realloc(dst_String->data, dst_String->capacity*=2);
// Append the characters preceding the match and the replacement text to
// dst_String and update the size of dst_String.
memcpy(dst_String->data+dst_String->size, src_String->data+pos
, match[0]-pos);
memcpy(dst_String->data+dst_String->size+match[0]-pos, replacement
, replacement_Size);
dst_String->size+=match[0]-pos+replacement_Size;
// Update pos to continue searching after the current match.
pos=match[1];
}
pcre2_code_free(regex);
// Allocate more memory for dst_String if there is not enough space for
// the characters following the last match (or the entire src_String if
// there was no match).
while(dst_String->size+src_String->size-pos>dst_String->capacity)
dst_String->data=realloc(dst_String->data, dst_String->capacity*=2);
// Append the characters following the last match (or the entire src_String
// if there was no match) to dst_String and update the size of dst_String.
memcpy(dst_String->data+dst_String->size, src_String->data+pos
, src_String->size-pos);
dst_String->size+=src_String->size-pos;
}
int main(void){
char const * const count_Info[]={
"agggtaaa|tttaccct",
"[cgt]gggtaaa|tttaccc[acg]",
"a[act]ggtaaa|tttacc[agt]t",
"ag[act]gtaaa|tttac[agt]ct",
"agg[act]taaa|ttta[agt]cct",
"aggg[acg]aaa|ttt[cgt]ccct",
"agggt[cgt]aa|tt[acg]accct",
"agggta[cgt]a|t[acg]taccct",
"agggtaa[cgt]|[acg]ttaccct"
}, * const replace_Info[][2]={
{"tHa[Nt]", "<4>"},
{"aND|caN|Ha[DS]|WaS", "<3>"},
{"a[NSt]|BY", "<2>"},
{"<[^>]*>", "|"},
{"\\|[^|][^|]*\\|", "-"}
};
string input={malloc(16384), 16384}, sequences={malloc(16384), 16384};
int postreplace_Size;
// Read in input from stdin until we reach the end or encounter an error.
for(int bytes_Read;
(bytes_Read=fread(input.data+input.size, 1, input.capacity-input.size
, stdin))>0;)
// Update the size of input to reflect the newly read input and if
// we've reached the full capacity of the input string then also double
// its size.
if((input.size+=bytes_Read)==input.capacity)
input.data=realloc(input.data, input.capacity*=2);
#pragma omp parallel
{
pcre2_match_context * mcontext=pcre2_match_context_create(NULL);
pcre2_jit_stack * const stack=pcre2_jit_stack_create(16384, 16384, NULL);
pcre2_jit_stack_assign(mcontext, NULL, stack);
pcre2_match_data * mdata=pcre2_match_data_create(16, NULL);
// Find all sequence descriptions and new lines in input, replace them
// with empty strings, and store the result in the sequences string.
#pragma omp single
{
replace(">.*\\n|\\n", "", &input, &sequences, mcontext, mdata);
free(input.data);
}
// Have one thread start working on performing all the replacements
// serially.
#pragma omp single nowait
{
// We'll use two strings when doing all the replacements, searching
// for patterns in prereplace_String and using postreplace_String to
// store the string after the replacements have been made. After
// each iteration these two then get swapped. Start out with both
// strings having the same capacity as the sequences string and also
// copy the sequences string into prereplace_String for the initial
// iteration.
string prereplace_String={
malloc(sequences.capacity), sequences.capacity, sequences.size
}, postreplace_String={
malloc(sequences.capacity), sequences.capacity
};
memcpy(prereplace_String.data, sequences.data, sequences.size);
// Iterate through all the replacement patterns and their
// replacements in replace_Info[].
for(int i=0; i<sizeof(replace_Info)/sizeof(char * [2]); i++){
replace(replace_Info[i][0], replace_Info[i][1]
, &prereplace_String, &postreplace_String, mcontext, mdata);
// Swap prereplace_String and postreplace_String in preparation
// for the next iteration.
string const temp=prereplace_String;
prereplace_String=postreplace_String;
postreplace_String=temp;
postreplace_String.size=0;
}
// If any replacements were made, they'll be in prereplace_String
// instead of postreplace_String because of the swap done after each
// iteration. Copy its size to postreplace_Size.
postreplace_Size=prereplace_String.size;
free(prereplace_String.data);
free(postreplace_String.data);
}
// Iterate through all the count patterns in count_Info[] and perform
// the counting for each one on a different thread if available.
#pragma omp for schedule(dynamic) ordered
for(int i=0; i<sizeof(count_Info)/sizeof(char *); i++){
int errorcode, count=0;
PCRE2_SIZE erroroffset, pos=0;
PCRE2_SIZE *match=pcre2_get_ovector_pointer(mdata);
// Compile and study pattern.
pcre2_code * regex=pcre2_compile((PCRE2_SPTR)count_Info[i]
, PCRE2_ZERO_TERMINATED, 0, &errorcode, &erroroffset, NULL);
pcre2_jit_compile(regex, PCRE2_JIT_COMPLETE);
// Find each match of the pattern in the sequences string and
// increment count for each match.
while(pcre2_jit_match(regex, sequences.data, sequences.size
, pos, 0, mdata, mcontext)>=0){
count++;
// Update pos to continue searching after the current match.
pos=match[1];
}
pcre2_code_free(regex);
// Print the count for each pattern in the correct order.
#pragma omp ordered
printf("%s %d\n", count_Info[i], count);
}
pcre2_match_context_free(mcontext);
pcre2_jit_stack_free(stack);
pcre2_match_data_free(mdata);
}
free(sequences.data);
// Print the size of the original input, the size of the input without the
// sequence descriptions & new lines, and the size after having made all the
// replacements.
printf("\n%d\n%d\n%d\n", (int)input.size, (int)sequences.size
, postreplace_Size);
return 0;
}
64-bit Ubuntu quad core
gcc (Ubuntu 10.3.0-1ubuntu1) 10.3.0
MAKE:
/usr/bin/gcc -pipe -Wall -O3 -fomit-frame-pointer -march=ivybridge -fopenmp regexredux.gcc-5.c -o regexredux.gcc-5.gcc_run -lpcre2-8
rm regexredux.gcc-5.c
1.66s to complete and log all make actions
COMMAND LINE:
./regexredux.gcc-5.gcc_run 0 < regexredux-input5000000.txt
PROGRAM OUTPUT:
agggtaaa|tttaccct 356
[cgt]gggtaaa|tttaccc[acg] 1250
a[act]ggtaaa|tttacc[agt]t 4252
ag[act]gtaaa|tttac[agt]ct 2894
agg[act]taaa|ttta[agt]cct 5435
aggg[acg]aaa|ttt[cgt]ccct 1537
agggt[cgt]aa|tt[acg]accct 1431
agggta[cgt]a|t[acg]taccct 1608
agggtaa[cgt]|[acg]ttaccct 2178
50833411
50000000
27388361
Rust implementation code and compilation details
// The Computer Language Benchmarks Game
// https://salsa.debian.org/benchmarksgame-team/benchmarksgame/
//
// contributed by Tom Kaitchuck
// contributed by Ryohei Machida
extern crate libc;
extern crate pcre2_sys;
extern crate rayon;
use crate::pcre2::Regex;
use rayon::prelude::*;
use std::cmp;
use std::io::{self, Read};
use std::mem;
use std::sync::mpsc;
mod pcre2 {
use pcre2_sys::*;
use std::ffi::c_void;
use std::ptr;
struct MatchData {
match_context: *mut pcre2_match_context_8,
match_data: *mut pcre2_match_data_8,
jit_stack: *mut pcre2_jit_stack_8,
ovector_ptr: *const usize,
}
impl MatchData {
fn new(code: *mut pcre2_code_8) -> Self {
let match_context =
unsafe { pcre2_match_context_create_8(ptr::null_mut()) };
assert!(
!match_context.is_null(),
"failed to allocate match context"
);
let match_data = unsafe {
pcre2_match_data_create_from_pattern_8(code, ptr::null_mut())
};
assert!(
!match_data.is_null(),
"failed to allocate match data block"
);
let jit_stack = unsafe {
pcre2_jit_stack_create_8(16384, 16384, ptr::null_mut())
};
assert!(!jit_stack.is_null(), "failed to allocate JIT stack");
unsafe {
pcre2_jit_stack_assign_8(
match_context,
None,
jit_stack as *mut c_void,
)
};
let ovector_ptr =
unsafe { pcre2_get_ovector_pointer_8(match_data) };
assert!(!ovector_ptr.is_null(), "got NULL ovector pointer");
MatchData { match_context, match_data, jit_stack, ovector_ptr }
}
}
impl Drop for MatchData {
fn drop(&mut self) {
unsafe {
pcre2_jit_stack_free_8(self.jit_stack);
pcre2_match_data_free_8(self.match_data);
pcre2_match_context_free_8(self.match_context);
}
}
}
pub struct Regex {
pattern: &'static str,
ctx: *mut pcre2_compile_context_8,
code: *mut pcre2_code_8,
match_data: MatchData,
}
impl Regex {
pub fn new(pattern: &'static str) -> Regex {
let ctx =
unsafe { pcre2_compile_context_create_8(ptr::null_mut()) };
assert!(!ctx.is_null(), "could not allocate compile context");
// compile and generate ast
let (mut error_code, mut error_offset) = (0, 0);
let code = unsafe {
pcre2_compile_8(
pattern.as_ptr(),
pattern.len(),
0,
&mut error_code,
&mut error_offset,
ctx,
)
};
assert!(!code.is_null(), "Failed to compile pattern");
// JIT compile
let error_code =
unsafe { pcre2_jit_compile_8(code, PCRE2_JIT_COMPLETE) };
assert_eq!(
error_code, 0,
"Failed to JIT compile (error code: {:?})",
error_code
);
Regex { pattern, ctx, code, match_data: MatchData::new(code) }
}
pub fn pattern(&self) -> &str {
self.pattern
}
pub fn find_at<'s>(
&self,
subject: &'s [u8],
start: usize,
) -> Option<(usize, usize)> {
assert!(start <= subject.len());
// pcre2_jit_match is 10-20% faster than pcre2_jit_match, but it
// skips many sanity-checks and dangerous.
// See https://github.com/BurntSushi/rust-pcre2/pull/17 for details.
unsafe {
let rc = pcre2_jit_match_8(
self.code,
subject.as_ptr(),
subject.len(),
start,
0,
self.match_data.match_data,
self.match_data.match_context,
);
if rc > 0 {
Some((
*self.match_data.ovector_ptr,
*self.match_data.ovector_ptr.add(1),
))
} else {
assert!(rc == -1, "matching error (error code: {:?})", rc);
None
}
}
}
pub fn count<'s>(&self, subject: &'s [u8]) -> usize {
let mut count = 0;
let mut last_match = 0;
while let Some((_, e)) = self.find_at(subject, last_match) {
count += 1;
last_match = e;
}
count
}
pub fn replace<'s, 'a, 'o>(
&self,
subject: &'s [u8],
alt: &'a [u8],
out: &'o mut Vec<u8>,
) {
let mut last_match = 0;
while let Some((s, e)) = self.find_at(subject, last_match) {
out.extend_from_slice(&subject[last_match..s]);
out.extend_from_slice(alt);
last_match = e;
}
out.extend_from_slice(&subject[last_match..]);
}
pub fn replace_inplace<'s, 'a>(
&self,
subject: &'s mut Vec<u8>,
alt: &'a [u8],
) {
let mut last_match = 0;
let mut last_write = 0;
while let Some((s, e)) = self.find_at(subject, last_match) {
assert!(e - s >= alt.len());
subject.copy_within(last_match..s, last_write);
last_write += s - last_match;
subject[last_write..last_write + alt.len()]
.copy_from_slice(alt);
last_write += alt.len();
last_match = e;
}
subject.copy_within(last_match.., last_write);
subject.truncate(last_write + (subject.len() - last_match));
}
}
impl Drop for Regex {
fn drop(&mut self) {
unsafe {
pcre2_code_free_8(self.code);
pcre2_compile_context_free_8(self.ctx);
}
}
}
// Regex matching causes mutation of match_data, so this Regex doesn't
// implement Sync.
unsafe impl Send for Regex {}
}
/// Get the number of bytes in the stdin socket
#[cfg(any(
target_os = "linux",
target_os = "android",
target_os = "macos",
target_os = "freebsd",
target_os = "dragonfly",
target_os = "openbsd",
))]
#[inline]
fn stdin_size_hint() -> Option<usize> {
use libc::{ioctl, FIONREAD, STDIN_FILENO};
let mut len: libc::c_int = 0;
if unsafe { ioctl(STDIN_FILENO, FIONREAD, &mut len as *mut _) } != -1 {
Some(len as usize)
} else {
None
}
}
#[cfg(not(any(
target_os = "linux",
target_os = "android",
target_os = "macos",
target_os = "freebsd",
target_os = "dragonfly",
target_os = "openbsd",
)))]
#[inline]
fn stdin_size_hint() -> Option<usize> {
None
}
fn count_reverse_complements(sequence: mpsc::Receiver<Vec<u8>>) -> Vec<String> {
// Search for occurrences of the following patterns:
let variants = vec![
Regex::new("agggtaaa|tttaccct"),
Regex::new("[cgt]gggtaaa|tttaccc[acg]"),
Regex::new("a[act]ggtaaa|tttacc[agt]t"),
Regex::new("ag[act]gtaaa|tttac[agt]ct"),
Regex::new("agg[act]taaa|ttta[agt]cct"),
Regex::new("aggg[acg]aaa|ttt[cgt]ccct"),
Regex::new("agggt[cgt]aa|tt[acg]accct"),
Regex::new("agggta[cgt]a|t[acg]taccct"),
Regex::new("agggtaa[cgt]|[acg]ttaccct"),
];
let sequence = sequence.recv().unwrap();
variants
.into_par_iter()
.map(|variant| {
let count = variant.count(&*sequence);
format!("{} {}", variant.pattern(), count)
})
.collect()
}
fn find_replaced_sequence_length(sequence: mpsc::Receiver<Vec<u8>>) -> usize {
// Replace the following patterns, one at a time:
let substs = vec![
(Regex::new("tHa[Nt]"), &b"<4>"[..]),
(Regex::new("aND|caN|Ha[DS]|WaS"), &b"<3>"[..]),
(Regex::new("a[NSt]|BY"), &b"<2>"[..]),
(Regex::new("<[^>]*>"), &b"|"[..]),
(Regex::new("\\|[^|][^|]*\\|"), &b"-"[..]),
];
let mut buf = sequence.recv().unwrap();
substs[0].0.replace_inplace(&mut buf, substs[0].1);
substs[1].0.replace_inplace(&mut buf, substs[1].1);
{
// the length of tmp will be at most 1.5 * buf.len() bytes because
// substs[2] replaces two characters with triple characters.
let mut tmp = Vec::with_capacity(buf.len() * 3 / 2);
substs[2].0.replace(&buf, substs[2].1, &mut tmp);
mem::swap(&mut buf, &mut tmp);
}
substs[3].0.replace_inplace(&mut buf, substs[3].1);
substs[4].0.replace_inplace(&mut buf, substs[4].1);
buf.len()
}
// allocate at least 2 pages
const MALLOC_OVERHEAD: usize = 16;
const MIN_ALLOC_SIZE: usize = 4096 * 2 - MALLOC_OVERHEAD;
fn main() {
let mut input_len = 0;
let mut sequence_len = 0;
let mut result = 0;
let mut counts = Vec::new();
let (tx1, rx1) = mpsc::channel();
let (tx2, rx2) = mpsc::channel();
rayon::scope(|s| {
let input_len = &mut input_len;
let sequence_len = &mut sequence_len;
let result = &mut result;
let counts = &mut counts;
s.spawn(move |_| {
let mut capacity =
stdin_size_hint().map_or(MIN_ALLOC_SIZE, |s| s + 1);
capacity = cmp::max(capacity, MIN_ALLOC_SIZE);
let mut input = Vec::with_capacity(capacity);
io::stdin().read_to_end(&mut input).unwrap();
*input_len = input.len();
Regex::new(">[^\n]*\n|\n").replace_inplace(&mut input, b"");
*sequence_len = input.len();
tx1.send(input.clone()).unwrap();
tx2.send(input).unwrap();
});
s.spawn(move |_| {
*result = find_replaced_sequence_length(rx1);
});
s.spawn(move |_| {
*counts = count_reverse_complements(rx2);
})
});
for variant in counts {
println!("{}", variant)
}
println!("\n{}\n{}\n{:?}", input_len, sequence_len, result);
}
64-bit Ubuntu quad core
rustc 1.55.0 (c8dfcfe04 2021-09-06)
LLVM version: 12.0.1
MAKE:
/opt/src/rust-1.55.0/bin/rustc -C opt-level=3 -C target-cpu=ivybridge --C codegen-units=1 -L /opt/src/rust-libs --extern libc=/opt/src/rust-libs/liblibc-08b6b7209eea639f.rlib regexredux.rs -o regexredux.rust-7.rust_run
10.30s to complete and log all make actions
COMMAND LINE:
./regexredux.rust-7.rust_run 0 < regexredux-input5000000.txt
PROGRAM OUTPUT:
agggtaaa|tttaccct 356
[cgt]gggtaaa|tttaccc[acg] 1250
a[act]ggtaaa|tttacc[agt]t 4252
ag[act]gtaaa|tttac[agt]ct 2894
agg[act]taaa|ttta[agt]cct 5435
aggg[acg]aaa|ttt[cgt]ccct 1537
agggt[cgt]aa|tt[acg]accct 1431
agggta[cgt]a|t[acg]taccct 1608
agggtaa[cgt]|[acg]ttaccct 2178
50833411
50000000
27388361
Will/Could Rust replace C at any time in the future
Rust has the potential to replace C++ and some other low-level languages. But this does not apply to C. Although C has 50 years of history, it has managed to remain its simple design. In our post above, we called C as a "nicer assembly" because it's nothing more. The best non-bloat language.
On the other hand, Rust is a good and well-designed language, it has to have a complex and non-standard design to solve the security solutions it deals with. The multitude of concepts the language offers, and the new features added in each version puts Rust in a different category against C.
C11 change logs(11 years after C99):
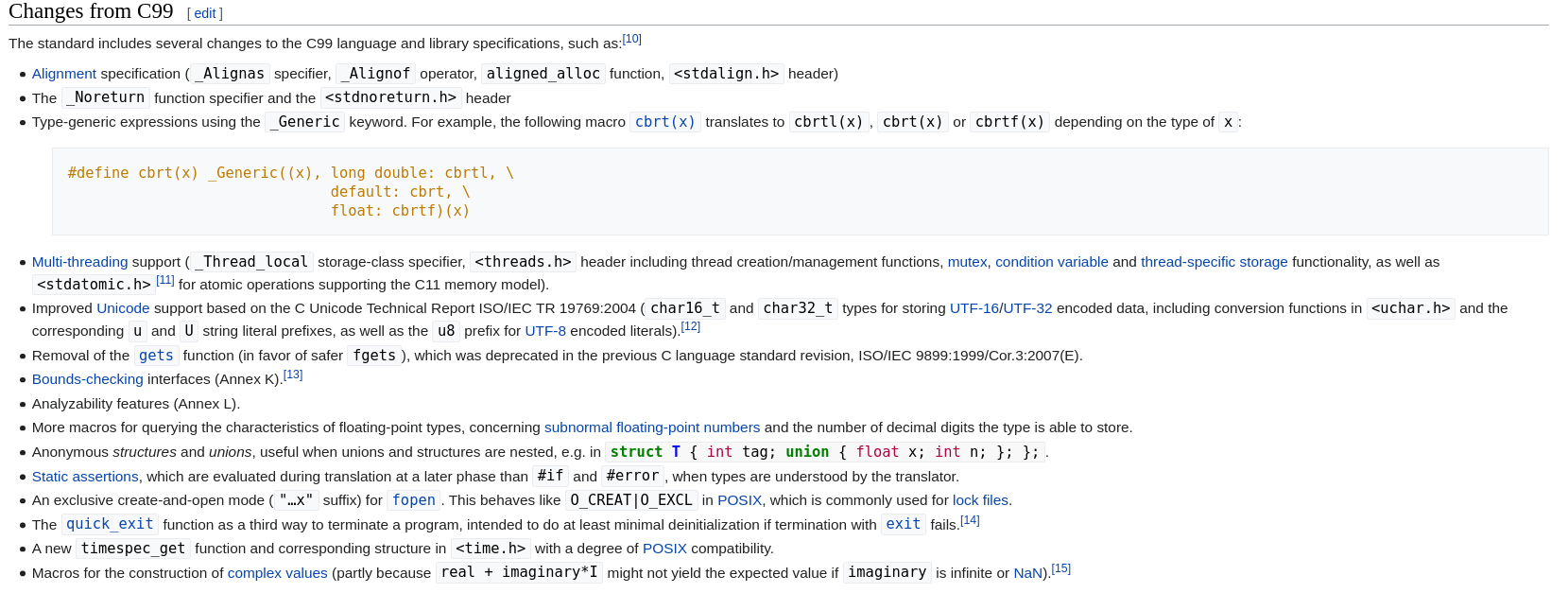
C17 change logs(7 years after c11):

Rust change logs of minor releases in 3 months:
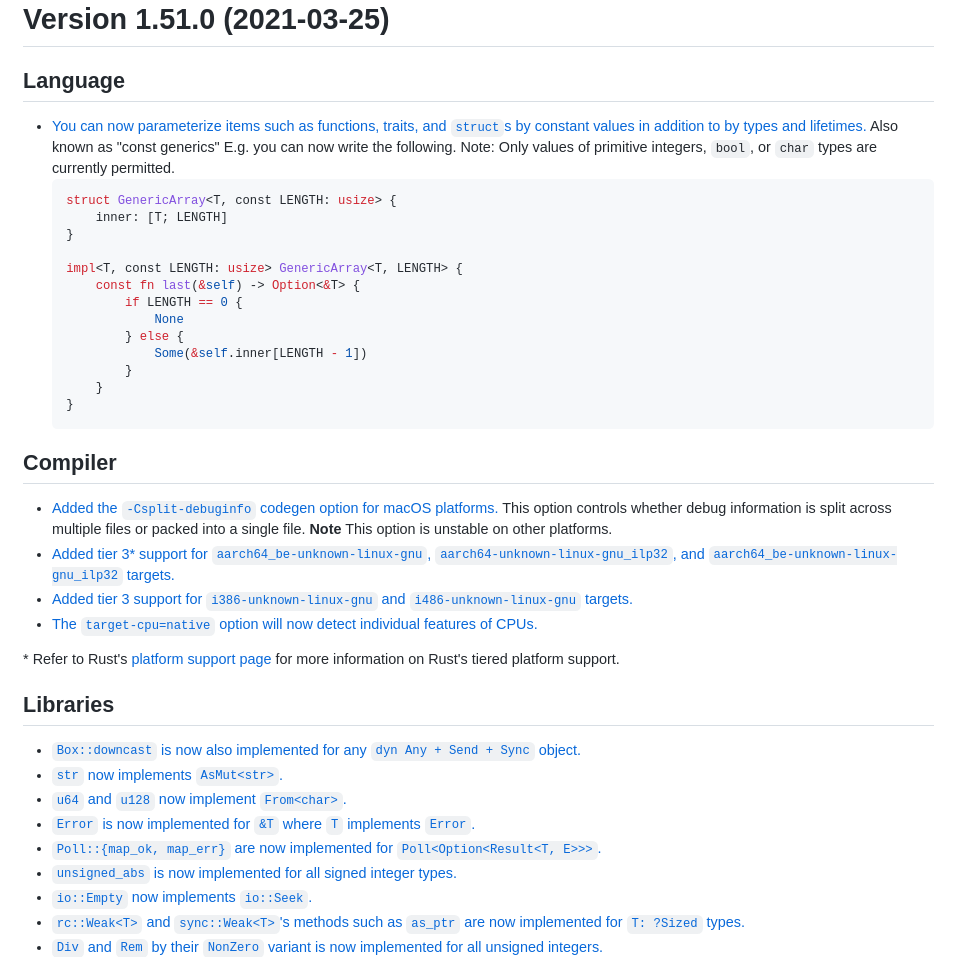
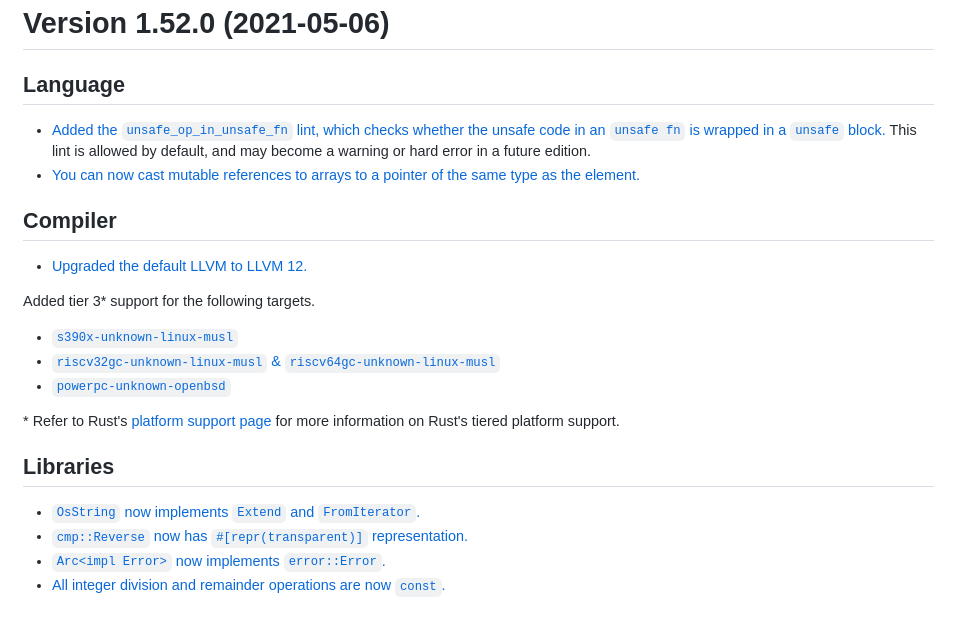
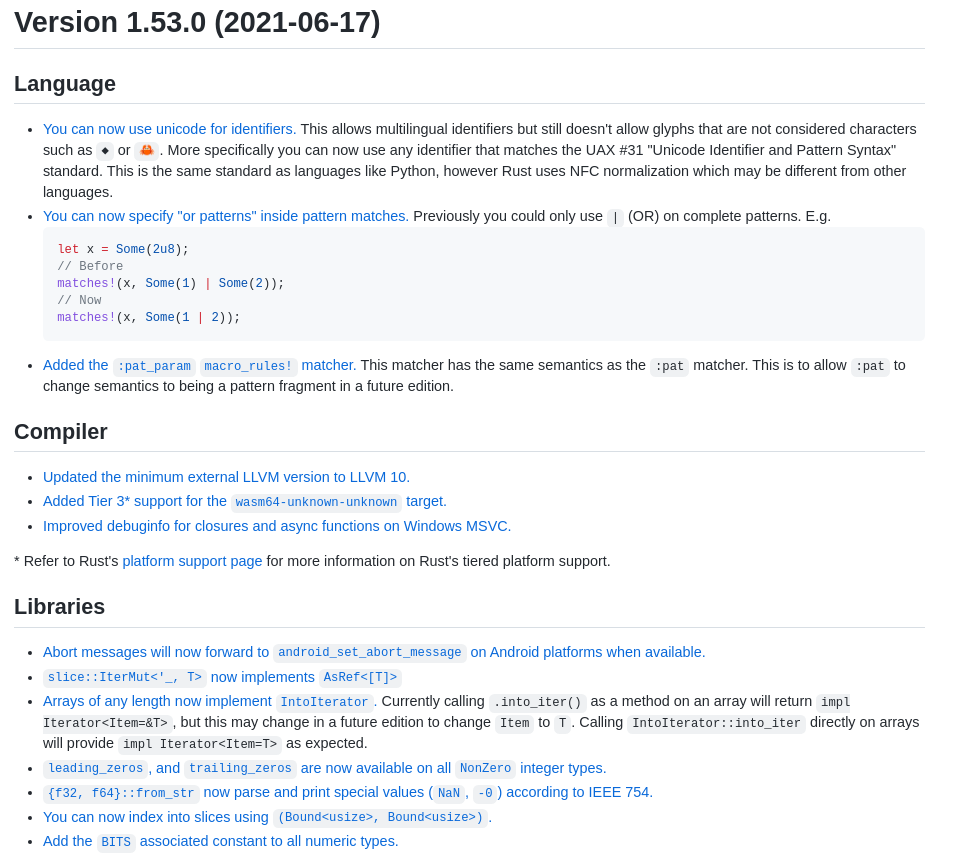
Therefore, in my honest opinion, C can only be replaced with a better C(even more simpler, faster and definetly safer). Not with a language that has too many features and keep adding innovations.
Is C outdated language
The design of the C language may be insufficient to be a high-level (compared to languages like Java, C# or even Rust, C++) language. Therefore, to people working with high-level languages, C can give the impression of an outdated language. From that perspective, they're right. Because in C, even simple programs can stretch things out since it doesn't have high-level template functions. In fact, this is exactly what we expect from the system language. It provides assembly abstraction and does not compromise on speed. This is one of the reasons it is used in the Linux kernel.
When Rust is unsafe
Although Rust is an inherently safe language, Rust also offers unsafe ways to build programs. Since Rust provides security with static analysis at the time of compilation, in some cases, you may need to handle security yourself and resort to unsafe ways. You can implement memory and thread-safe algorithms, just as thousands of crate.io libraries do by using unsafe ways. But then, the program may encounter problems such as dangling references, memory leaks, or some undefined behavior since the compiler expects you to handle security problems.
Therefore, you should be very careful using external codes, libraries. Rust isn't magically 100% safe. A library that contains unsafe implementations may cause problems in projects that use this library. Rust doesn't convert programs to be safe magically. Putting the "safe, secure" tags on every project written in Rust is a trick to spreading this misconception. One of the most critical problems of the Rust community is that they do not take this fact into account and ignore it. That's why crates.io has thousands of libraries with security issues.
Conclusion
Where and when to pick Rust?
This is a quite relative question, however, choosing Rust for corporate projects can be beneficial for the company. Because as a company, it is easier to trust a proven compiler than trusting the engineers. Project maintenance and reviews will be easier compared to C. At the same time, the mistakes that the newly hired engineer can make in the project will be limited.
Where and when to pick C?
If the target platform of the project is not supported by Rust (GCC's platform support is much wider than Rust for now and for at least the next 5-6 years), when the compilation time matters, and to keep things simple and avoid messing with Rust's compiler rules.